Facebook začne trénovat AI i na vašich datech. Máte poslední šanci to odmítnout

Od 27. května začne Meta trénovat svou AI na veřejném obsahu uživatelů v EU. Pokud nesouhlasíte, musíte vyplnit formulář, jinak dáváte tichý souhlas.
AI od Mety se brzy začne učit na vašem obsahu
Společnost Meta v minulých měsících oznámila, že se její generativní inteligence začne trénovat na příspěvcích uživatelů v EU, a to už od 27. května 2025. To znamená, že vše, co přidáte na sociální sítě Facebook, Instagram nebo Threads, bude skenovat umělá inteligence za účelem jejího zlepšení. Stejně je to na sociální síti X, kde se Grok učí ze všech příspěvků uživatelů.
Naštěstí, pokud s tím nesouhlasíte, můžete to dát společnosti najevo pomocí speciálního digitálního formuláře. Ten můžete najít na stránkách Facebooku a jeho vyplnění je velmi jednoduché. Stačí vyplnit jen e-mail, na který máte sociální sítě registrované a do textového pole napsat důvod, proč nechcete, aby byla AI na vašem obsahu trénována. Po odeslání formuláře ještě dorazí potvrzující e-mail.
Meta ubezpečuje, že umělá inteligence se rozhodně nebude učit ze soukromých zpráv, jelikož ty jsou šifrované. Trénovat bude pouze na veřejném obsahu, jako jsou statusy nebo fotografie. I přesto, že pošlete svůj nesouhlas, se skenování od umělé inteligence nemusíte vyhnout, protože tato pravidla neplatí, pokud snímek vaší konverzace nebo komentáře sdílí další osoba.
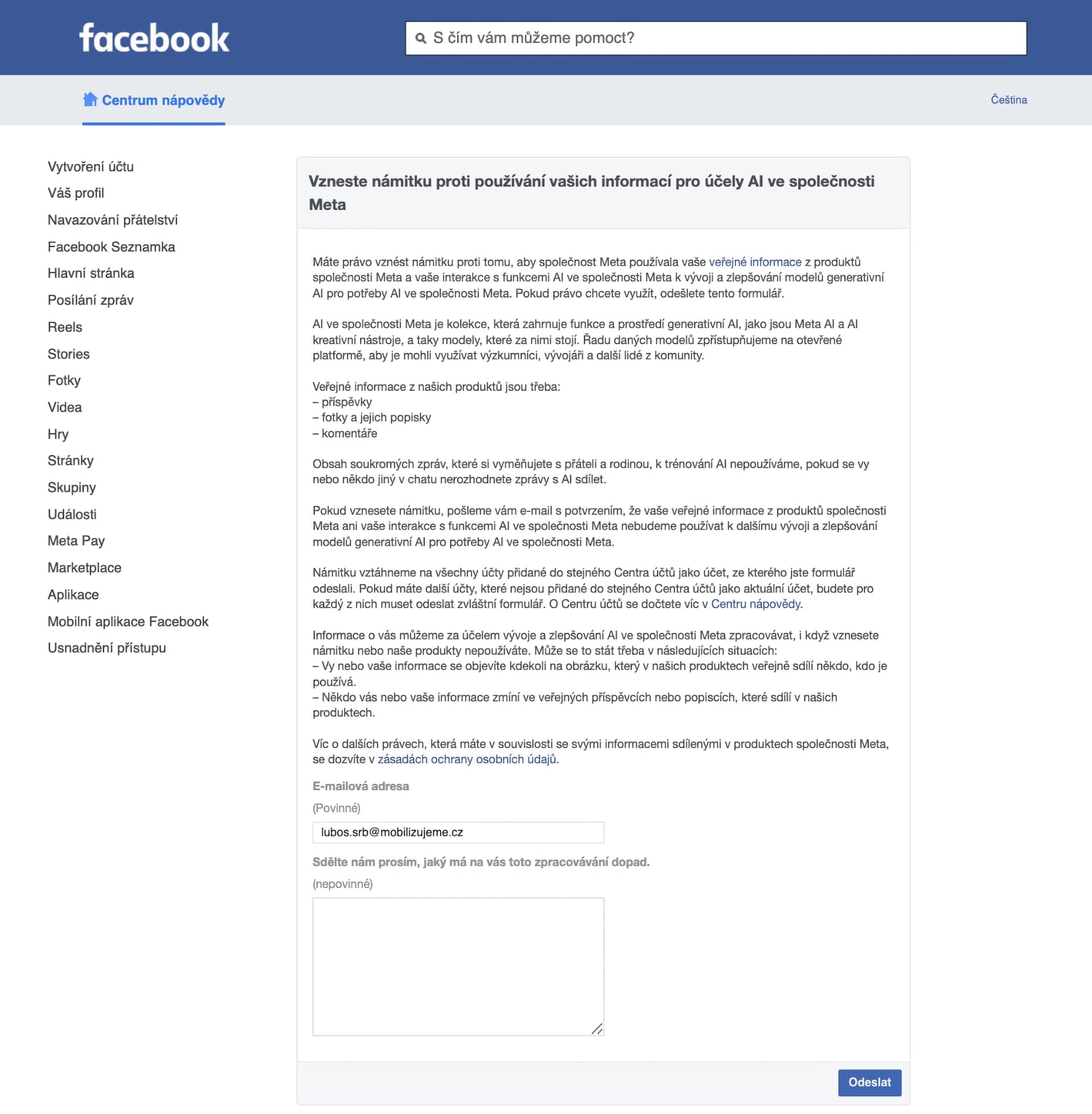
Neodeslání formuláře znamená tichý souhlas
Pokud do 27. května formulář neodešlete, znamená to, že jste s novými pravidly souhlasili. A pokud formulář pošlete po zvoleném datu, už je pozdě a z vašich dat se AI bude učit. Takže nyní máte poslední příležitost, jak vyjádřit svůj nesouhlas. Pod společnost Meta spadá i WhatsApp, ale z toho se umělá inteligence učit nebude, protože by tím narušila soukromí uživatelů.
Tento krok je od Mety velmi logický, jelikož pro vytrénování umělé inteligence je třeba obrovské množství dat a proč nevyužít ta, která jsou přístupná ve vlastních službách. Sociální sítě jsou pro AI skvělým místem k učení, protože je na nich obrovské množství různorodého obsahu. Každopádně Meta nedělá nic neobvyklého – podobně k tomu přistupují i konkurenti Google a OpenAI.
Učení na uživatelských příspěvcích je bohužel standardem ve vývoji umělé inteligence. Chatbot ChatGPT se například učil na článcích různých zpravodajských webů. Nástroj na generování obrázků Veo 3 od Googlu se zase učí na některých YouTube videích. Pro správný rozvoj umělé inteligence jsou zkrátka data klíčová.
Zdroje: Facebook formulář, Facebook
Autor článku

Richard se od dětství zajímá o technologie – od počítačů a mobilů po vše s chytrými funkcemi. Novinky ze světa technologií jsou pro něj nejen prací, ale i vášní. Ve svých textech spojuje nadšení s přehledem a důrazem na srozumitelnost.
Richard se od dětství zajímá o technologie – od počítačů a mobilů po vše s chytrými funkcemi. Novinky ze světa technologií jsou pro něj nejen prací, ale i vášní. Ve svých textech spojuje nadšení s přehledem a důrazem na srozumitelnost.